By John Fernandes modified Sep 15, 2025
~ 2 minutes to read
You might be surprised to learn how much the choice between a data warehouse and a data lake affects your bottom line. Given that 2.5 quintillion bytes of data are created every day and 463 exabytes are expected to be created by 2025, businesses must find smarter ways to handle their growing storage needs. Think about it: One terabyte of storage in an internal data warehouse costs about $468,000 per year, yet data lakes can leverage object storage services like Amazon S3 for about $0.023 per gigabyte.
We have personally witnessed the impact that choosing one of these architectures has on long-term budgets. By combining the flexibility of data lakes with the structural dependencies of warehouses, data lake houses effectively offer the best of both worlds. They also allow for schema-on-write and schema-on-read strategies, which can greatly reduce processing costs. By 2025, Gartner predicts that more than 95% of new digital workloads will move to cloud-native platforms, underscoring the need for affordable data management solutions. We’ll explain in detail what a data lake is, examine the data warehouse vs. lake house argument, and help you decide which choice will deliver the most cost savings for your company in 2025.
A data lake house is a contemporary architectural development that combines warehouses and data lakes. This hybrid approach combines the flexibility and cost-effectiveness of data lakes with the data management and ACID transaction capabilities of data warehouses.
The data structures and management features found in warehouses are incorporated into the lakehouse concept, which is based on the inexpensive storage typically used for data lakes. Business intelligence and machine learning on all forms of data — structured, semi-structured, and unstructured — are made possible by this single architecture.
Unlike traditional warehouses, lakehouses often use an extract, load, transform (ELT) approach, which stores data in its unprocessed state before transformation. With optimized metadata layers and indexing algorithms designed specifically for data science applications, this approach offers greater flexibility without sacrificing performance.
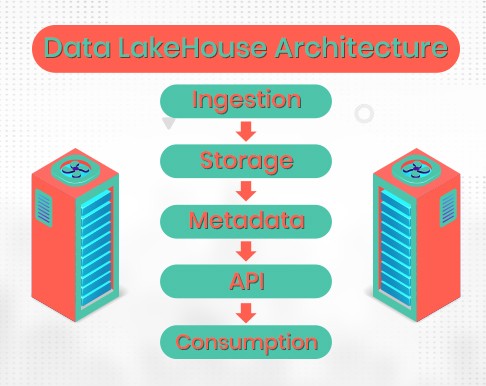
In this situation, data is useful. It collects real-time data — continuous streams of data — and batch data — large amounts of data analyzed at once — from a variety of sources. The majority of lakes operate on extract, load, and transform (ELT), although some may use extract, transform, and load (ETL). Before transforming it for analysis, it loads the raw data.
A data lake is a type of scalable cloud storage system where data is held.
All stored data is monitored by this layer. Lake houses use the metadata layer to enforce governance and quality standards, implement schemas, and index data for fast queries.
This layer provides a variety of tools and apps to link and collaborate with data for deeper exploration.
Applications for business intelligence (BI), machine learning (ML), and other initiatives are used here to provide users with access to data.
Because the architecture separates compute and storage resources, scaling is easy. Open source formats and technologies, such as Apache Parquet and Apache Iceberg, are frequently used in data lakes.
Businesses can use pre-built solutions or choose different components to build their own lake houses.
Benefits of reduced data duplication Because data lakes store all of a company’s data in a single system, there is less risk that the same data will be stored more than once.
By eliminating the need for different storage systems, they save money by using a lower-cost storage option.
For advanced data analysis, data lakes integrate well with leading business tools (such as Tableau and Power BI). To make it easier for analysts to interact with data, they also support multiple data science programming languages and open formats.
Data lakes make it easier to manage who has access to data and maintain its security and integrity.
The main drawback is that data lakes are still in their infancy, making it difficult to predict whether they will reach their full potential. They may take some time to catch up with other leading big data storage solutions.
Real-time analytics is made possible by the ability of lake houses to handle streaming data. Live analysis of data from various sources enables businesses to make decisions and gain insights more quickly.
Large-scale machine learning activities are supported by data lakes. Both raw and processed data are easily accessible to data scientists. This makes it possible to train and test models more successfully.
These systems have strong security and governance features. It encourages data sharing and collaboration while giving businesses control over data access and compliance.
Many data lakes can be used with leading business intelligence programs. This makes it easy for non-technical users to access information through user-friendly dashboards and reports.
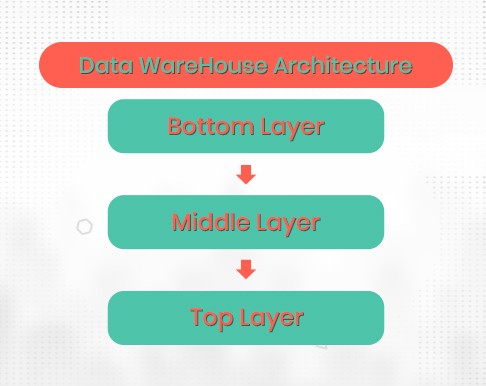
For nearly 30 years, data warehouses have been the backbone of business intelligence, evolving into specialized repositories of structured data. Information from multiple related sources across the organization is combined into a single central store through a data warehouse. These systems handle data through Extract, Transform, Load (ETL) pipelines, where the data undergoes transformations to meet predefined schemas before being stored.
In particular, data warehouses excel at using SQL queries to present clean, structured data for BI analytics. However, they are constrained when it comes to organizing unstructured data and supporting machine learning tasks. Many traditional warehouses use proprietary formats, which often limit their ability to use advanced analytics.
Three layers are typically present in the architecture: a middle analytical layer (usually based on OLAP), a top tier with business user reporting capabilities, and a bottom tier where data is moved through ETL procedures. This structure prioritizes data consistency and query performance, albeit at the cost of increased storage costs.
Data enters this point from various sources. Extract, Transform, and Load (ETL) is used to clean and organize it. The data is often stored in a relational database.
This layer includes tools such as SQL engines and online analytical processing (OLAP) systems. These technologies help in data analysis and querying. This allows deep insights to be gained directly from the warehouse.
This includes reporting tools and a user-friendly interface. This allows users to easily analyze the data whenever they need it.
Data warehouses were typically located on-site. Many are now available as cloud services or in the cloud. Additionally, some businesses combine the two.
Structured data is ideal for traditional data warehouses. This is a result of their rigid organization and reliance on relational database systems. However, many modern warehouses are also capable of managing unstructured and semi-structured data. For this type of data, many businesses favor using lake houses or data lakes.
Data warehouses collect information in a standardized way, which facilitates the trust and efficient use of data.
Large volumes of unprocessed data are transformed into meaningful information through data warehouses. They provide companies with a solid foundation for data analysis, enabling them to tackle challenging problems and reach well-informed conclusions.
Businesses can quickly connect their analytical tools to warehouses because they hold reliable and consistent data, which speeds up reporting and decision-making.
Decision makers can assess risks and gain a deeper understanding of client needs when all relevant data is kept in one place. This results in faster and smarter improvements to products and services.
Structured data is most effective for them. Unstructured or semi-structured data can be difficult to handle, making them less suitable for some sophisticated applications.
The costs associated with setting up and managing a data warehouse can be unpredictable. For example, a server with one terabyte of storage and 100,000 queries per month can cost around $468,000 per year. Additionally, they require frequent maintenance and updates, which increases the cost.
Data warehouses are used by business intelligence and reporting organizations to collect historical data, which can then be used and analyzed to create dashboards, reports, and visualizations. To improve inventory and sales strategies, for example, a retail business might use a data warehouse to examine sales patterns over several years.
Data in a business is often scattered across multiple systems and divisions. This data can be centralized in a data warehouse so that it can be easily accessed and analyzed. For example, a business can integrate inventory records, sales data, and customer information to provide a complete picture of performance.
Businesses can use a data warehouse to monitor KPIs. This facilitates timely decision-making and process monitoring. A data warehouse, for example, might be used by a manufacturing organization to assess production efficiency and identify areas that need improvement.
By keeping track of past data that can be examined to predict future patterns, data warehouses enable predictive modeling. For example, a financial organization can predict future loan defaults by analyzing historical data and modifying its lending practices accordingly.
Data compliance is subject to stringent requirements in many businesses. Data management and storage in accordance with these regulations can be facilitated by a data warehouse.
A scalable cloud-based data warehouse for data processing, analytics, and storage is called Snowflake. The entire data warehouse can handle multi-cloud settings as it is designed on top of Google Cloud, Microsoft Azure, and Amazon Web Services. As a fully self-managed SaaS data cloud platform, Snowflake eliminates the need to set up data marts, data lakes, and data warehouses while facilitating secure data sharing.
Businesses can use this platform without having to install, configure, or manage any hardware or software. Everything is ready to use right out of the box. Snowflake Data Warehouse empowers businesses with a modern cloud-based platform that combines speed, scalability, and flexibility, enabling streamlined data management, advanced analytics, and better decision-making across industries. Here are the benefits:
• Snowflake automatically scales up or down to handle different workloads, ensuring fast query performance without overpaying for unused resources.
• Businesses can securely share live data with teams, departments, or external partners without complex integrations.
• Handles structured and semi-structured data (JSON, Avro, Parquet) in a single platform, reducing the need for multiple tools and simplifying analytics.
A type of data warehouse that is hosted in the cloud is called a cloud-based data warehouse. Large amounts of data can be stored and analyzed using this type of data warehouse, which is highly scalable. They are great options for growing companies. Here are three businesses that can benefit from a cloud-based data warehouse:
• A startup that lacks the funds to build and manage an on-premises data warehouse but needs to store a lot of data.
• A multinational company that needs to store and process data from multiple geographical locations.
• A business that needs a flexible and scalable solution as its data storage requirements change over time.
A central location that houses all of an organization’s data is called an enterprise data warehouse. It offers a single source of “truth” and is designed to manage large amounts of data from multiple sources.
One of the benefits of an enterprise data warehouse is its ability to combine data from multiple sources and present a complete perspective.
Because of this, it is a great option for businesses that need to review a lot of data from many sources. Here are three businesses that can benefit from an enterprise data warehouse:
• A large store that must examine sales information from multiple sites and sales channels.
• A healthcare provider that must consolidate patient information from multiple systems and locations.
• A financial organization that must consolidate information from multiple departments, such as banking and investment services.
A logical view created by merging data from multiple sources is called a virtual data warehouse. Without physically consolidating the data, the goal is to present a single, coherent view. The ability to keep data physically separate is one of the key benefits of adopting this approach.
If you need to analyze data from multiple different sources in one place, consider using a virtual data warehouse.
Here are three businesses that can benefit from a virtual data warehouse:
• A business with multiple databases containing different types of data that want to create a single view without having to physically combine the data.
• A company that wants to build a data warehouse without spending money on actual hardware.
• A business that wants to test the idea of a data warehouse before spending money on a real one.
By offering sophisticated and integrated analytics services, such as serverless data lakes and cloud data warehouses, AWS Analytics Services helps businesses turn their data into answers faster. Getting insights faster means less time preparing the plumbing and configuring cloud analytics services to work together. AWS helps you do this by providing:
• An easy way to start implementing a variety of analytics workloads and build data lakes and warehouses.
• A network, compute, and storage infrastructure in the cloud that is secure and scalable to the demands of analytics workloads.
• A fully integrated analytics stack with a mature range of analytics tools, covering all common use cases and using open file formats, standard SQL languages, open source engines, and platforms.
• Lowest cost, highest scalability, and best performance for analytics.
A schema-on-write model governs how data warehouses work. It indicates that when data enters the system, the schema—the structure and rules that govern the data—are applied.
This approach enforces strict data integrity, which increases query performance. However, careful planning is essential throughout the data integration process.
A data mart is a more condensed and targeted form of data warehousing. Typically, it is designed for specific company divisions, such as finance or marketing departments.
A data mart provides specialized data sets for quick access and easy querying, while a data warehouse handles enterprise-wide data integration.
Finding the best solution for your needs can be helped by being aware of the key distinctions between data warehouses and data lakehouses. A summary of their key differences can be seen below.
Direct model training on large data sets is made possible by data lake houses’ natural integration with machine learning tools such as TensorFlow, PyTorch, and Databricks ML. Data warehouses sometimes need to export data to external systems for analysis, and they have limited support for machine learning.
For example: A tech corporation can build AI-powered recommendation systems within a data lake house using Databricks.
Data lake houses are ideal for a variety of workloads because they can manage a wide range of data formats. They support:
• Structured Data: Relational databases and sales transactions are examples of structured data.
• Semi-structured data: Sensor readings, JSON user profiles
• Unstructured Data: IoT logs, images, and audio files are examples of unstructured data.
Data warehouses are better suited for traditional business processes like financial reporting and analytics because they contain mostly structured and occasionally semi-structured data.
For example: A retail business might use a data lakehouse to examine transaction records, social media data, and clickstream logs to gauge client mood.
Data lakehouses are great for big data analytics and machine learning because they can handle both batch and real-time processing. Large datasets are processed quickly thanks to their distributed architecture. Data warehouses offer fast, reliable performance for structured data and excel at handling transactional workloads and SQL-based queries.
For example: A data lakehouse’s ability to handle streaming data could be beneficial for a financial organization looking for real-time fraud detection.
Data lakehouses reduce the cost of ETL preparation by using inexpensive cloud storage (such as Amazon S3 and Azure Data Lake Storage) and supporting schema-on-read. Due to their proprietary formats, ETL processing, and structured storage, data warehouses are typically more expensive.
For example: A data lakehouse can be less expensive than a data warehouse for a company that needs inexpensive storage for both raw and processed data.
Data lakehouses accommodate multi-engine processing and scale to petabytes of data. Data warehouses have difficulty handling large unstructured datasets, but they scale well for structured data.
For example: While a traditional warehouse may struggle to handle IoT data, a telecom operator can scale a lakehouse to process billions of calls records every day.
Business intelligence, regulatory compliance, and structured data are all best served by data warehouses. If you rely on highly structured, fast, and reliable analytics, a data warehouse is the best option.
• Best for datasets that are well-structured and have clear schema constraints.
• Use in situations where analytics and reporting depend on performance and consistency.
For example: A business that uses a data warehouse to analyze structured sales data from its extensive network of stores. This makes it easy to monitor stock levels, find top-selling items, and streamline replenishment procedures on a moment-to-moment basis.
• Ideal for generating reports and dashboards for decision makers.
• Supports tools with optimized query performance, such as Tableau and Power BI.
For example: A financial services company that provides quarterly earnings reports to stakeholders.
• Designed for industries with strict audit and data accuracy standards.
• Offers reliable storage for compliance reporting, medical data, and financial documents.
For example: A financial institution ensures compliance with regulations such as Basel III and GDPR by storing and analyzing transaction data in a data warehouse. This centralized approach helps prevent fraud and manage audit trails.
• Use in strategic decision-making and long-term trend analysis.
• This is ideal for sectors that require multi-year data insights, such as manufacturing or energy.
For example: To maximize production, an energy provider reviews past electricity usage.
When you need a scalable, adaptable system that supports AI, machine learning, and real-time analytics and can manage structured, semi-structured, and unstructured data, a data lake house is the best option.
• The best platform for combining unstructured, semi-structured, and structured data.
• Promotes dynamic data access and reduces silos.
For example: A streaming service that stores metadata, user activity records, and video content.
• Ideal for experimentation, model training, and raw data exploration.
• Allows flexibility in schema-on-read for a variety of datasets.
For example: A business that processes GPS logs, driver ratings, and raw trip data using a data lakehouse. Machine learning models for fraud detection, dynamic pricing, and route optimization are powered by this data.
• Use for applications that need to process and make inferences on data almost instantly.
• Supports dynamic use cases, such as IoT analytics and fraud detection.
For example: Real-time sensor data is transmitted to the lakehouse architecture by IoT-enabled cars. This enables the business to track vehicle performance, identify anomalies, and distribute software updates over the air.
• Reduces costs by storing raw data without much preprocessing.
• Effectively scales for businesses that generate large amounts of data.
For example: A social networking business that uses a data lakehouse to store and process huge amounts of unprocessed user-generated content, including text, images, and videos. They can perform sentiment analysis, identify popular articles, and improve ad targeting with this configuration.
While lakehouses and data warehouses have diverse uses, many businesses combine the systems to balance flexibility, affordability, and performance.
With a hybrid strategy, you can use a lake for big data, artificial intelligence, and machine learning while storing structured data in a warehouse for quick analytics.
A hybrid strategy uses a two-tier approach:
1. A data lake houses semi-structured and raw data that is adaptable, scalable, and affordable.
Uses cloud object storage (Amazon S3, Azure Data Lake, Google Cloud Storage) to store a variety of data types, including unstructured, semi-structured, and structured data.
Provides flexibility to data scientists and AI/ML teams by leveraging schema-on-read.
Allows real-time import of data from streaming platforms, event logs, and IoT devices.
2. Data in the data warehouse that has been cleansed and organized (suitable for instant analytics and BI).
Before being stored in the warehouse, the data is filtered, processed, and organized using tools such as Snowflake, Redshift, BigQuery, and Synapse.
Uses schema-on-write to improve query performance and ensure data consistency.
Provides instant access to operational reports, dashboards, and business intelligence.
• For ML/AI workloads, you need flexible data storage and fast BI reporting.
• Since your organization deals with both structured and unstructured data, schema-on-write and schema-on-read capabilities are essential.
• Using Lakehouse for economical raw data storage and a warehouse for structured, high-value analytics will help you reduce costs.
• You should preserve controlled historical records while digesting and processing data in real time.
Your architecture choice today will lay the foundation for future expansion, creativity, and competitive advantage. The right data architecture can power your company’s analytics capabilities and provide the foundation for real-time insights, AI, and machine learning at scale.
The decision to deploy a data lake, data warehouse, or data lake house is not simply a technical one. Rather, it is a long-term strategic one that can facilitate smarter decision-making, streamline operations, and create opportunities for future innovation. While each architecture has its own advantages, the ideal choice is one that best fits your company’s specific requirements, expansion goals, and data aspirations.
Role-based access control (RBAC), established schemas, and centralized governance are characteristics of data warehouses.
Date Lakehouses requirements:
• Fine-grained access constraints (such as Unity Catalog and AWS Lake Formation).
• Tracking datasets at the storage level through metadata management.
• Consistency in monitoring data quality for schema-on-read context.
The migration process includes:
• Assessing Data: When reviewing data, distinguish between structured and unstructured sources.
• Choosing a platform: Lakehouses can be supported by tools such as Data Bricks, Apache Iceberg, or Snowflake.
• Developing ETL pipelines: For transformation and ingestion, use DBT or Apache Spark.
• Optimizing Performance: Use caching, partitioning, and indexing techniques to maximize performance.
Unified and hybrid designs are becoming more popular in the industry.
• Lakehouse features are being added to warehouse systems through cloud platforms.
• Serverless data warehousing is increasing scalability and cost-effectiveness.
• Data ownership is being distributed across teams through data mesh designs.
Data professionals can stay ahead of the curve by staying informed about these developments.
AI/ML works best with lakes because they:
• Store unstructured, semi-structured, and structured data to train models.
• Use Databricks ML and Spark to enable feature engineering in real time.
• Support on-demand model training without the need for data export.
Unlike warehouses, leakhouses enable data scientists to deal directly with raw data.
John Fernandes is content writer at YourDigiLab, An expert in producing engaging and informative research-based articles and blog posts. His passion to disseminate fruitful information fuels his passion for writing.





